Ever wondered why some systems run smoothly for years while others crash constantly? The secret lies in one powerful practice: system maintenance. It’s not just about fixing things—it’s about preventing problems before they happen.




What Is System Maintenance and Why It Matters

At its core, system maintenance refers to the regular and systematic actions taken to keep a system—whether it’s software, hardware, or an entire IT infrastructure—running efficiently and reliably. This includes everything from updating software to replacing worn-out hardware components.
Defining System Maintenance in Modern Tech
In today’s digital-first world, system maintenance has evolved beyond simple repairs. It now encompasses proactive monitoring, performance tuning, security patching, and lifecycle management. According to the ISO/IEC 14764 standard, software maintenance includes modification of software after delivery to correct faults, improve performance, or adapt to a changed environment.
- Corrective maintenance: fixing bugs or failures after they occur.
- Adaptive maintenance: adjusting systems to new environments (e.g., OS upgrades).
- Perfective maintenance: enhancing functionality or usability.
- Preventive maintenance: reducing future issues through proactive optimization.
The Hidden Cost of Ignoring System Maintenance
Organizations that neglect system maintenance often face severe consequences. A report by Gartner found that unplanned downtime costs businesses an average of $5,600 per minute—over $300,000 per hour. These costs stem from lost productivity, data corruption, customer dissatisfaction, and even regulatory fines.
“Failure to maintain systems is not a technical oversight—it’s a strategic risk.” — IT Infrastructure Expert, 2023
The 7 Pillars of Effective System Maintenance
To build a resilient and high-performing system, you need a structured approach. Here are seven foundational pillars that define world-class system maintenance practices.
1. Preventive Maintenance: Stop Problems Before They Start
Preventive system maintenance involves scheduled checks and updates designed to prevent system failure. This includes disk cleanups, log file rotation, database indexing, and firmware updates.
- Scheduled patching cycles (e.g., monthly security updates).
- Hardware inspections (e.g., checking server fans and power supplies).
- Automated health checks using monitoring tools like Nagios or Zabbix.
For example, a company running a large-scale e-commerce platform might schedule weekly database optimizations to prevent slowdowns during peak traffic hours. This is a classic example of preventive system maintenance in action.
2. Predictive Maintenance: Using Data to Forecast Failures
Predictive maintenance takes prevention a step further by using real-time data and analytics to predict when a component is likely to fail. This is especially common in industrial IoT and cloud infrastructure.
- Monitoring CPU temperature, disk I/O latency, and memory usage trends.
- Using machine learning models to detect anomalies.
- Integrating with APM (Application Performance Monitoring) tools like New Relic or Datadog.
For instance, predictive algorithms can analyze hard drive S.M.A.R.T. data to warn administrators weeks before a disk failure occurs. This allows for seamless replacement without service interruption.
3. Corrective Maintenance: Fixing What’s Broken
Despite best efforts, failures happen. Corrective system maintenance focuses on diagnosing and resolving issues after they occur. Speed and accuracy are critical here.
- Incident response protocols and escalation matrices.
- Root cause analysis (RCA) using frameworks like the 5 Whys or Fishbone diagrams.
- Rollback procedures for failed updates or deployments.
A well-documented corrective maintenance plan ensures that when a server crashes or a database becomes unresponsive, the team can restore service quickly and minimize downtime.
System Maintenance in Different Environments
System maintenance isn’t a one-size-fits-all process. The strategies and tools vary significantly depending on the environment—be it on-premise, cloud, hybrid, or embedded systems.
On-Premise Infrastructure Maintenance
On-premise systems require hands-on physical and digital maintenance. This includes server room climate control, UPS battery checks, and local backup verification.
- Regular physical inspections of networking hardware.
- Manual patching of legacy applications not compatible with automated tools.
- Local disaster recovery drills (e.g., simulating power outages).
Organizations with on-premise data centers often rely on IT technicians to perform scheduled maintenance windows, typically during off-peak hours to minimize disruption.
Cloud-Based System Maintenance
In cloud environments, much of the underlying hardware maintenance is handled by the provider (e.g., AWS, Azure, Google Cloud). However, customers are still responsible for maintaining their applications, configurations, and data.
- Managing virtual machine images and container updates.
- Configuring auto-scaling and load balancing policies.
- Ensuring compliance with shared responsibility models.
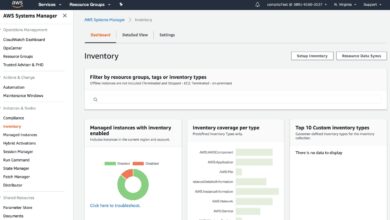
For example, AWS provides tools like Systems Manager and CloudWatch to automate patching and monitor system health, enabling robust system maintenance without physical access.
Hybrid and Edge Computing Maintenance
Hybrid systems combine on-premise and cloud resources, requiring a unified maintenance strategy. Edge computing adds complexity, as devices are often geographically dispersed.
- Remote monitoring and over-the-air (OTA) updates for edge devices.
- Synchronizing maintenance schedules across environments.
- Using centralized configuration management tools like Ansible or Puppet.
Manufacturing plants using IoT sensors on production lines rely heavily on remote system maintenance to keep operations running without sending technicians to every site.
The Role of Automation in System Maintenance
Automation is revolutionizing how organizations approach system maintenance. By reducing human error and increasing efficiency, automated tools are becoming indispensable.
Automated Patch Management
Manual patching is time-consuming and error-prone. Automated patch management tools ensure that all systems receive critical updates on time.
- Tools like Microsoft WSUS, Red Hat Satellite, or third-party solutions like ManageEngine.
- Scheduled patch deployments during maintenance windows.
- Post-patch verification to confirm successful installation.
For example, a financial institution might use automated patching to ensure all teller terminals are updated with the latest security fixes every weekend, minimizing risk without disrupting business.
Self-Healing Systems and AI-Driven Maintenance
Emerging technologies are enabling systems to detect and fix issues autonomously. Self-healing architectures can restart failed services, reroute traffic, or scale resources dynamically.
- Kubernetes auto-healing pods that restart when containers crash.
- AI-powered monitoring tools that predict and mitigate performance bottlenecks.
- Automated failover systems in database clusters.
Google’s SRE (Site Reliability Engineering) team uses AI-driven anomaly detection to identify and resolve issues before users are affected—showcasing the future of intelligent system maintenance.
Scripting and Orchestration for Routine Tasks
Simple scripts can automate repetitive maintenance tasks like log rotation, disk cleanup, and backup verification.
- Bash or PowerShell scripts for Linux and Windows systems.
- Cron jobs or Task Scheduler for recurring execution.
- Orchestration platforms like Jenkins or GitLab CI/CD for complex workflows.
A media company might use a script to automatically compress and archive old video files every month, freeing up storage space and improving system performance.
Best Practices for Implementing System Maintenance
Successful system maintenance isn’t just about tools—it’s about processes, people, and planning. Here are proven best practices to ensure your maintenance strategy delivers results.
Create a Comprehensive Maintenance Plan
A formal system maintenance plan outlines what needs to be done, when, by whom, and how. It should include:
- Asset inventory (hardware, software, versions).
- Maintenance schedules (daily, weekly, monthly).
- Checklists for each task.
- Escalation procedures for critical issues.
This plan should be documented and accessible to all relevant teams, ensuring consistency and accountability.
Establish Regular Maintenance Windows
Scheduled maintenance windows minimize disruption by allowing updates and repairs during low-traffic periods.
- Communicate planned downtime to users in advance.
- Use rolling updates for distributed systems to avoid full outages.
- Monitor system stability post-maintenance.
For example, a SaaS company might schedule maintenance every Sunday at 2 AM local time for each region, ensuring global service continuity.
Monitor, Measure, and Improve
Effective system maintenance requires continuous feedback. Use KPIs like Mean Time Between Failures (MTBF), Mean Time to Repair (MTTR), and system uptime to measure success.
- Track incident frequency and resolution times.
- Conduct post-mortems after major outages.
- Adjust maintenance strategies based on performance data.
Regular audits and reviews help refine the maintenance process, turning it into a continuous improvement cycle.
Common Challenges in System Maintenance
Even with the best intentions, organizations face obstacles in maintaining their systems effectively. Recognizing these challenges is the first step to overcoming them.
Lack of Skilled Personnel
Many companies struggle to find IT professionals with the right mix of technical and analytical skills for modern system maintenance.
- Invest in training and certifications (e.g., CompTIA, AWS, Microsoft).
- Partner with managed service providers (MSPs) for specialized support.
- Encourage cross-training within IT teams.
According to a 2023 (ISC)² Cybersecurity Workforce Study, there’s a global shortage of 3.4 million cybersecurity and IT professionals—making talent acquisition a major hurdle.
Legacy Systems and Technical Debt
Older systems often lack support, documentation, or compatibility with modern tools, making maintenance difficult and risky.
- Document legacy system behavior thoroughly.
- Isolate legacy systems from critical networks.
- Plan gradual migration or modernization projects.
For example, a government agency running a 20-year-old mainframe may need to maintain it with outdated tools while planning a phased transition to cloud-based alternatives.
Security Risks During Maintenance
Maintenance activities can introduce vulnerabilities if not handled securely—e.g., using unpatched temporary systems or exposing credentials.
- Use secure access methods (e.g., SSH, MFA).
- Audit all changes made during maintenance.
- Test patches in staging environments before deployment.
A single misstep during a system update can lead to data breaches or compliance violations, making security a top priority in every maintenance task.
The Future of System Maintenance
As technology evolves, so does the nature of system maintenance. Emerging trends are reshaping how we keep systems healthy and resilient.
AIOps and Intelligent Maintenance
Artificial Intelligence for IT Operations (AIOps) combines big data and machine learning to automate and enhance system maintenance.
- Correlating events from multiple sources to identify root causes.
- Automating incident response and ticket routing.
- Providing predictive insights for capacity planning.
Companies like IBM and Splunk offer AIOps platforms that help IT teams move from reactive to proactive maintenance models.
Zero-Touch Maintenance in Autonomous Systems
The goal of zero-touch maintenance is to eliminate manual intervention entirely. Systems self-monitor, self-diagnose, and self-repair.
- Autonomous cloud networks that reconfigure during outages.
- Self-updating firmware in IoT devices.
- AI-driven resource allocation in data centers.
While still emerging, zero-touch maintenance is already being used in telecom networks and large-scale cloud infrastructures.
Sustainability and Green Maintenance
As environmental concerns grow, system maintenance is also focusing on energy efficiency and sustainability.
- Optimizing server utilization to reduce power consumption.
- Using renewable energy-powered data centers.
- Extending hardware lifespan through careful maintenance.
Google, for instance, uses AI to optimize cooling in its data centers, reducing energy use by up to 40%—a prime example of green system maintenance.
Real-World Case Studies in System Maintenance
Learning from real-world examples can provide valuable insights into what works—and what doesn’t—in system maintenance.
Case Study 1: Netflix’s Chaos Engineering
Netflix pioneered Chaos Engineering to test system resilience. Their tool, Chaos Monkey, randomly shuts down production instances to ensure the system can handle failures gracefully.
- Proactively identifies weak points in architecture.
- Encourages robust design and automated recovery.
- Reduces downtime during real outages.
This aggressive form of system maintenance has made Netflix one of the most reliable streaming platforms globally.
Case Study 2: NASA’s Deep Space Network Maintenance
NASA maintains a global network of antennas to communicate with spacecraft. System maintenance here is mission-critical.
- Routine calibration and alignment of massive dish antennas.
- Redundant systems to ensure continuous communication.
- Remote diagnostics and repairs for distant installations.
Even a minor glitch can result in lost data from Mars rovers, making precision and reliability non-negotiable in their maintenance protocols.
Case Study 3: Hospital IT System Maintenance
Hospitals rely on uninterrupted access to patient records, imaging systems, and monitoring devices.
- Maintenance performed during low-activity hours (e.g., early morning).
- Redundant systems for life-critical applications.
- Strict compliance with HIPAA and other regulations.
A major hospital in the U.S. reduced system downtime by 70% after implementing a centralized monitoring and automated patching system—demonstrating the life-saving impact of effective system maintenance.
What is system maintenance?
System maintenance refers to the ongoing process of inspecting, updating, repairing, and optimizing systems—whether hardware, software, or networks—to ensure reliability, security, and performance. It includes preventive, corrective, adaptive, and perfective activities.
Why is system maintenance important?
It prevents system failures, reduces downtime, enhances security, improves performance, and extends the lifespan of IT assets. Neglecting maintenance can lead to data loss, security breaches, and costly outages.
How often should system maintenance be performed?
The frequency depends on the system type and criticality. Some tasks (like security patches) should be done monthly or even weekly, while hardware inspections might occur quarterly. A formal maintenance plan helps determine the right schedule.
Can system maintenance be automated?
Yes, many aspects of system maintenance can and should be automated—such as patching, backups, monitoring, and log rotation. Automation reduces human error, saves time, and ensures consistency across systems.
What tools are used for system maintenance?
Common tools include monitoring platforms (Nagios, Zabbix), patch management systems (WSUS, Ansible), APM tools (New Relic, Datadog), and AIOps platforms (Splunk, IBM Watson AIOps). The choice depends on the environment and scale.
System maintenance is not a luxury—it’s a necessity. From preventing costly downtime to securing sensitive data, the benefits are clear and far-reaching. By embracing preventive strategies, leveraging automation, and learning from real-world examples, organizations can build systems that are not only reliable but resilient. The future belongs to those who maintain not just to fix, but to thrive.
Further Reading: